[D/E] Kafka / REST Kafka

Kafka란 ?
카프카는 빠르고 확장 가능한 작업을 위해 데이터 피드의 분산 스트리밍, 파이프 라이닝 및 재생을 위한 실시간 스트리밍 데이터를 처리하기 위한 목적으로 설계된 오픈 소스 분산형 게시-구독 메시징 플랫폼입니다.
파이프라이닝: 한 번에 하나의 명령어만 실행하는 것이 아니라 하나의 명령어가 실행되는 도중에 다른 명령어의 실행을 시작함으로써 동시에 명령어 여러 개를 실행하는 방식
1. 구성요소 : Event, Producer, Consumer, Topic
- Event: Producer, Consumer가 데이터를 주고 받는 단위
- Producer: Kafka에 이벤트를 게시하는 클라이언트 어플리케이션
- Consumer: Topic을 구독하고 이로부터 얻어낸 이벤트를 처리하는 클라이언트 어플리케이션
- Topic: 이벤트가 쓰여지는 곳으로 Producer는 Topic에 이벤트를 게시, Consumer는 Topic으로부터 이벤트를 가져와 처리.
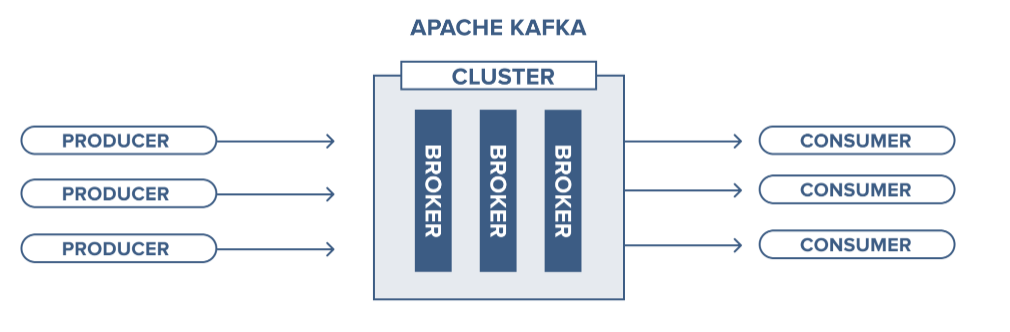
2. 특징
- Partition : Topic은 여러 Broker에 분산되어 저장, 분산된 Topic을 Partition이라 부름. 어떤 Event가 어떤 Partition에 저장될지는 Key에 의해 결정되며, 같은 key값을 가진 Event는 같은 Partition에 저장됨.
- Producer와 Consumer의 분리 : 별개로 동작함. 그로 인해 Scale In/Out 에 용이함
- Push / Pull 모델 : Broker가 Consumer에게 Push가 아닌 Consumer가 Broker에게 Pull하여 이벤트 처리, 이로인한 장점으로 다양한 소비자의 처리속도와 형태를 고려하지 않아도 된다, 또한 불피요한 지연없이 일괄처리를 통해 성능 향상 도모
- 소비된 메시지 추적(Commit과 Offset) : 메시지는 지정된 Topic에 전달되고, Topic은 다시 여러개의 Partition으로 나뉨. Partition으로 나뉨. Partition은 log로 칸을 나누어 순차적으로 append됨. 메시지의 상대적인 위치를 offset이라 함.
메시징 시스템은 Broker에게 소비된 메시지에 대한 메타데이터를 유지. 즉, 메시지가 Consumer에게 전달되면 Broker는 이를 로컬에 기록하거나 consumer의 승인을 기다림.
- Commit과 Offset : Consumer의 poll은 이전의 Commit한 offset이 존재하면 해당 offset값을 commit한다. 이어서 poll이 진행되면 방금 전 commiut한 offset 이후의 메시지를 읽어와 처리
Consumer가 메시지 소비를 승인해야 메시지 삭제, 하지만 Consumer가 승인하기 전에 Broker가 실패로 인지하면 같은 메시지를 여러번 Consumer가 가져갈 수 있음. 멱등성을 고려해야함. 특수한 상황으로 인해 여러번 받아서 여러번 처리다더라도 한번 처리한 것과 같은 결과를 가지도록 설계 해야함.
- Consumer Group : 하나의 Topic을 구독하는 여러 Consumer들의 모임. Partition을 담당하는 Consumer 가 처리 불가 상태가 되어버리면 Partition과 Consumer를 재 조정 하여, 남은 Consumer Group 내의 Consumer가 Partition을 적절하게 나누어 처리 Consumer Group내에서 Consumer들 간의 offset정보를 공유하고 있기 때문에, 특정 Consumer가 처리 불가 상태가 되었을 때, 해당 Consumer가 처리한 마지막 offset부터 처리 할 수 있다. Partition을 나머지 Consumer들이 나누어 처리하도록 하는 것을 Rebalance라고 하며, 이를 위해 Consumer Group가 필요하다.
Consumer Group내의 Consumer들은 각기 다른 Partition에 연결되어야 한다. 이렇게 함으로서 Consumer의 메시지 처리 순서를 보장하게 된다.
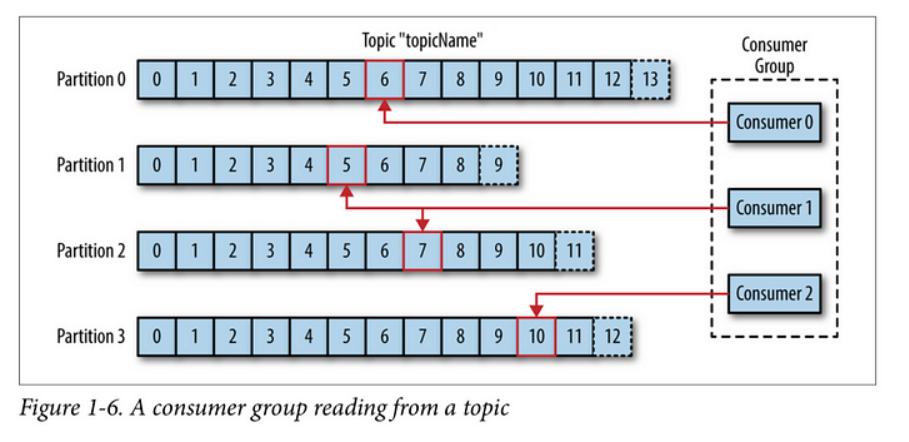
- Consumer의 확장 : Consumer 성능이 부족해 Scale In/Out 할 때, Patition은 Consumer 수 보다 많아야 한다.
- 메시지(이벤트) 전달 Concept 종류:
- At Most once (최대 한번) : 재 전송을 하지 않는다.
- At Least once (최소 한번) : 재 전송을 할 수 있다.
- Exactly once (정확히 한번) : 정확하게 한번 전달 되어야 함
- 그 외 정리 하면서 발견한 것 :
- 메모리가 아닌 디스크에 저장하여 서버 장애로 인한 데이터 손실은 없음
- 디스크가 순차적으로 저장되어 I/O가 줄어들음
- Partition의 읽고 쓰는 것은 리더 파이션에게만 해당되고 나머지 파티션에는 복제가 되는 것임
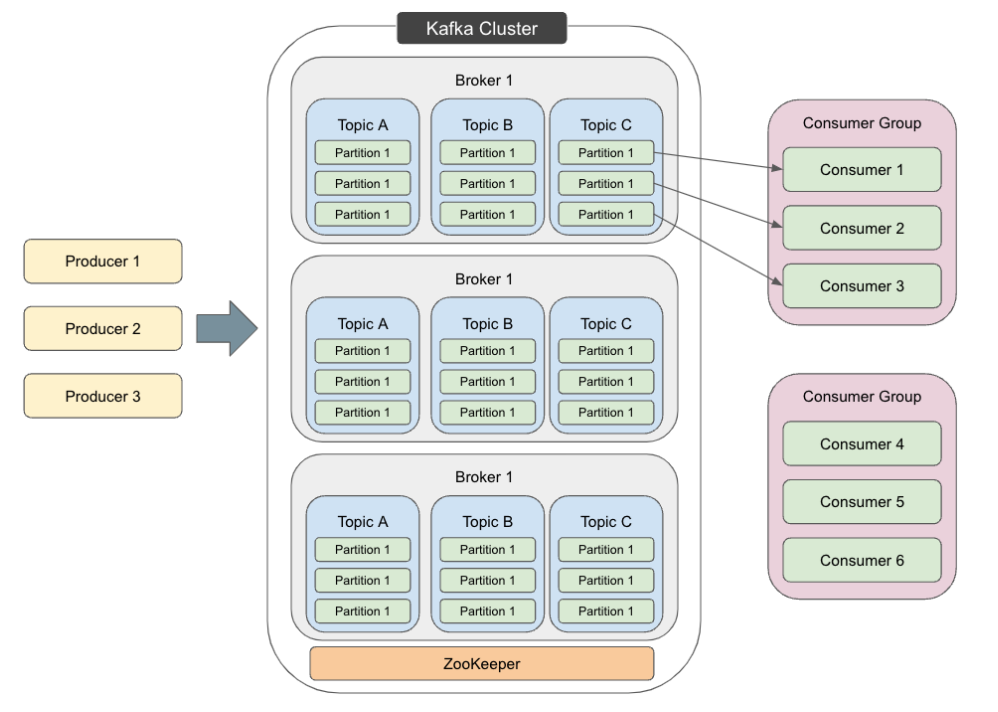
- kafka Cluster 이해를 돕는 사진
Kafka / REST Kafka 비교
- 통신 프로토콜 : Kafka는 네이티브 Kafka 프로토콜을 사용하여 데이터를 생산(Producer)하고 소비(Consumer)한다. 이는 Kafka 클러스터 간의 효율적인 통신을 가능 한다. 반면에, Kafka REST는 HTTP 프로토콜을 사용하여 데이터를 생산하고 소비한다.
- 데이터 형식 : Kafka는 바이트 배열(byte array) 기반의 데이터를 처리하며, 메시지의 형식에 대한 제약이 없다. 데이터는 직렬화(serialization)되어 Kafka 클러스터에 전송된다. Kafka REST는 JSON 형식의 데이터를 처리하며, RESTful API를 통해 JSON 메시지를 생산하고 소비할 수 있다.
- API 디자인 : Kafka는 Java, Scala, Python, Go 등 다양한 언어로 구현된 클라이언트 라이브러리를 제공하며, 다양한 Kafka 클라이언트를 사용하여 데이터를 생산하고 소비할 수 있다. Kafka REST는 HTTP 기반의 RESTful API를 제공하며, HTTP 요청과 응답을 통해 데이터를 생산하고 소비할 수 있다.
- 보안 : Kafka는 내장된 보안 기능을 제공하여 데이터를 암호화하고 인증 및 권한 부여를 지원한다. Kafka REST는 보안을 위해 HTTPS를 지원하며, 인증 및 권한 부여는 프록시 서버 레벨에서 처리된다.
- 클라이언트 유연성 : Kafka 클라이언트 라이브러리는 다양한 기능과 설정을 제공하며, 고급 데이터 처리 및 운영 요구 사항을 충족시킬 수 있다. 반면에, Kafka REST는 단순한 HTTP API를 제공하여 상대적으로 간단한 데이터 생산 및 소비 기능을 제공한다.
요약하자면, Kafka는 네이티브 Kafka 프로토콜을 사용하여 바이트 배열 형식의 데이터를 처리하며, 다양한 클라이언트 라이브러리를 제공하는 반면에, Kafka REST는 HTTP 프로토콜을 사용하여 JSON 형식의 데이터를 처리하고 RESTful API를 제공한다. 각각의 사용 사례와 요구 사항에 따라 적당한 방식을 선택하여 사용 하면 될 것같다.
